Building a Homelab, Part 5 - New Services and Hardening
November 9, 2024 | 15 min. read
This is the sixth post in a series about building my homelab. Read the previous posts here:
Taking Stock
In the ~6 months since I've gone all-in on Kubernetes (more on that in the previous post), I've had a pretty good experience with it. I've been able to add a ton of different software and services, and a good chunk of toil has been automated away. I won't lie, though; there have definitely been some growing pains. I'll go over all the fun new stuff I've installed first, before getting into gripes.
Speedtest-Tracker
Speedtest-Tracker was one of the first new services that I installed after the Kubernetes migration, mostly to see what it's like to install something on Kubernetes from scratch (rather than migrating an existing service into Kubernetes). I don't have a burning need to monitor my network speeds - other than to see how bad of a deal I'm getting from Spectrum - but it's kind of handy to have nonetheless.
I think the only issue I have with it is that it has an authentication/user account system, which seems a little unnecessary for a self-hosted internet speed test application. I mean, do I really care if anyone else on my homelab/local network sees how fast the network speeds are? I wouldn't mind this quite so much if I could just hook it up to the LDAP server so I only have to remember the one set of creds, but no such integration exists.
Postgres
Speedtest-Tracker required a Postgres server to store speedtest data, so I
decided to set one up within Kubernetes that all of my other services could also
use. Since the DB storage needs to be persistent, I just stuck an NFS
PersistentVolume on the Synology NAS that most of my lab's data is stored on.
I also didn't feel any particular need to do a crazy high-availability setup or
anything, so I just have a deployment with a single Postgres container that
mounts the storage to /var/lib/postgresql/data.
I'm pretty sure this setup will give some SREs indigestion, and I definitely
wouldn't do this for a real-deal production service. In that scenario, I'd
probably want a DB cluster living outside of k8s with high availability,
multiple read replicas, auto-scaling, and all the usual good stuff. The lab's
needs are a lot smaller than that, though, so I'm pretty comfortable leaving
things as they are now. I've read some other blogs and /r/homelab posts about
using
postgres-operator
to do some of that stuff in a self-hosted environment, so I might get around to
that when I want a learning experience.
Maybe the one semi-urgent thing that I really should do is set up automated backups. I'm really letting Jesus take the wheel when it comes to the NAS server; if it goes belly up, the homelab is pretty much toast (my k8s manifests and NixOS configs are in GitHub, but losing all that data would really, really suck).
Uptime Kuma
This is probably the first of the new services I set up to address a concrete, specific need. During (and immediately after) the migration, I didn't have a good sense of what was running properly and what might have crashed. Uptime Kuma is pretty much exactly what I wanted in a self-hosted monitoring solution. It's dead simple to set up, and has good support for a variety of different types of healthchecks (HTTP requests to arbitrary endpoints, DNS requests, gRPC, even custom support for SQL or game servers). I integrated this with the SMTP server I mentioned in part 3, so now I have email notifications whenever anything goes down.
Miniflux
As a self-hoster/FOSS enthusiast/blogger/etc., I've always loved the idea of RSS. I've had an RSS feed on my blog for years now, but I hadn't ever really used RSS, outside of a month-long stint of trying to use Emacs as an RSS reader with elfeed This was a pretty bad experience, for a few reasons. The feed and everything was stored locally in an SQLite database, so I couldn't actually consume my feed across different devices without setting up some kind of file syncing (maybe Syncthing would have been a good fit, but I feel like that would have been fiddly). Also, as an application running inside Emacs, there was no daemon constantly polling feeds for new posts so everything would be fetched at once whenever I would fire up elfeed. This would usually cause Emacs to hang for a good while, which was never fun. There were also a few times where Emacs had some trouble rendering the contents of RSS feed items, so more often than not I'd just open the item's link in a browser and read it. I love Emacs, I use it everyday, it's very cozy, but sometimes you've got to know when it's not the right tool for the job.. I figured this might be something that would fit self-hosting well, and boy was I right!
Miniflux is the absolute bomb. It's pretty simple to set up, it can store all its data on the Postgres server I set up, and I can integrate it with OIDC to authenticate with my LDAP creds. Checking all my RSS feeds on Miniflux has become a part of my daily routine, and I've even been able to find RSS feeds for some local newspapers (no idea how or why they exist since I can't imagine they're monetizable, but I'm not asking any questions) and start reading Real News™️ more often.
*arr Suite
I've been running Jellyfin and qBittorrent since well before the migration, so installing the *arr suite for automated media downloads and library management was a no-brainer addition. More specifically, I've installed the following services:
- Radarr, for movie library management and download automation
- Sonarr, like Radarr but for movies
- Prowlarr, an index manager to automate searches on trackers/UseNet providers
- Readarr, like Radarr/Sonarr but for eBooks.
Most of these services were pretty easy to set up when following the Servarr Wiki and TRaSH Guides. I had some initial growing pains when first setting up Radarr and Sonarr though; they really chugged during the initial import of my library, even though it's not that large (~500 movies, ~4,000 TV episodes).
All of these services have been a great success so far, other than Readarr. Readarr doesn't really play well with Calibre-Web, since (last I checked) Calibre won't actually import new books into the database unless they're uploaded directly via the Calibre (or Calibre-Web) UI. It also does this annoying thing where it treats authors and books similarly to how Sonarr treats TV shows and episodes, respectively. By default, it assumes that I want every book by any author in my library and tries to monitor/download any of those books that I don't already own. Additionally, it's pretty difficult to find eBooks on most public trackers, so the only books that I was able to get from Readarr were public domain books that I could have just downloaded from Project Gutenberg anyway. I'll give Readarr another couple weeks, and then I'll uninstall it if I haven't used it enough to change my mind.
Matrix (Synapse)
My personal phone is an Android, much to the chagrin of my iOS-using friends and partner. Other than the totally stupid "green bubbles" that occur when texting a non-iMessage device from iMessage, generally annoying things occur when texting: super compressed images, annoying bugs or inability to send videos, deliverability issues, etc. I just use Google Messages on my Android phone as my main SMS application, so I don't know what the deal is - I would imagine that Google would iron out those bugs if they expect people to use their phones for text messages. I'd like to solve these issues, but I'm not buying an iPhone anytime soon Mostly for cost reasons, since I don't really have a horse in the race of Android vs. iOS. I've definitely invested a good amount of time and effort in custom theming/custom launchers/etc. over the years that would be lost on iOS, and I would miss F-Droid for the few times I've had to reach for it, but I don't think there's anything in particular keeping me in the Android ecosystem. I have a Samsung Galaxy Watch that integrates really nicely, but I mostly just use it like a watch that gives me app notifications. There was a time a couple of years ago where I would have been loath to exit the Linux-ish comfort of Android and sell out to the proprietary walled garden of Apple, but I don't think I have that fight in me anymore.. I could just use something like Discord, but I have a silly profile pic and username and I'd like to keep that confined to my gaming buddies and friends from high school (I wish more software would think about the persona/multi-faceted identity problem). Slack is probably my favorite chat app in terms of UX, but it isn't really meant for 1-1 text messaging or ad hoc group chats. WhatsApp is a candidate, but (unlike two billion other people around the world) nobody in the US really uses WhatsApp.
Luckily, there's Matrix! It's a chat/text messaging protocol that's designed around self-hosting and federation, kind of like a modernized and Fediverse-y IRC. I won't kid myself into thinking that I can insist on all of my friends to join Matrix server; that's a great way to annoy them and never recieve a text message again. I figured that, at the very least, I can integrate it into the rest of my homelab and that anyone else with access can check it out if they're curious. Since it's self-hosted, I can also integrate it with other services or write as many bots as I want for automation, alerting, and general goofing around.
The Matrix protocol is exactly that - a protocol - so if you want to run a server, you have to pick an actual implementation. I went with Synapse, which is basically synonymous with the protocol itself since it's the reference implementation and was originally written by the Matrix Foundation (now it's maintained by Element, who also maintain the most popular Matrix client of the same name).
I won't lie this, was probably the trickiest thing that I've installed in the
homelab so far. Since I want the server to be accessible outside of the VPN or
my home network, I had to make the server's hostname (chat.janissary.xyz)
outside of the lab's internal domain (lab.janissary.xyz). I also wanted my
handle on Matrix to just be noah@janissary.xyz rather than
noah@chat.janissary.xyz, so I had to set up
delegation such
that my server's name is janissary.xyz but Matrix actually communicates with
chat.janissary.xyz. I also had to do add a DNS record to point
chat.janissary.xyz to my VPS at janissary.xyz, and then edit the nginx
configs to proxy that traffic to the Synapse container in the homelab over the
VPS' Tailscale connection. Synapse has OIDC out of the
box, and it was
thankfully pretty easy to setup. All I had to do was follow the Authelia
docs, and I was
able to log in via Authelia with my LDAP creds once I'd installed a Matrix
client (I went with Element, since it seemed the most
featureful and well-maintained).
Once all that was done, I joined a public server to see if my server could
federate and see all the messages other people were sending. I thought I had
misconfigured something at first, since it looked like every room was empty -
all I could see was a loading spinner where the room's messages should be. Turns
out, I made the rookie mistake of using sqlite as the backing storage when the
docs specifically point out that using sqlite is a bad
idea.
Once I had migrated everything to Postgres, performance was still a little
subpar, but definitely tolerable. Browsing rooms on a server is still pretty
slow, but I don't really do that enough for it to be an issue. Synapse still
seems to do poorly when joining larger rooms; it takes a minute or two for all
the messages to actually appear. I wonder if this might just be a necessary evil
of federation, though - from the server logs, I can see there's a huge deluge of
requests coming from and going to other self-hosters (at least, I'm guessing
they're self-hosting based on the server names being things like avocadoom.de
or catgirl.cloud or nyanbinary.rs). In the worst case, every message in a
room could come from a seperate federated server, so getting all the messages in
a room could take O(number of federated servers) Matrix API requests. I think
some of the servers that I'm on that bridge between Discord/Matrix also don't
work very well, since there's definitely a lot of messages I can see in the
corresponding Discord channels that don't appear in Matrix. I probably can't
fault Matrix/Synapse for that, though - it could result from any number of
issues caused by server admins, bridge software, etc. - but (reliable) bridges
to more established communication mediums were one of the selling points of
Matrix for me.
Overall, the experience with Element/Synapse/Matrix has been pretty positive. I've been able to convince/cajol my girlfriend into using it for our text conversations, and it's been a big hit. Being able to finally send non-deep-fried pictures and videos is the biggest boon, but the extra features like emoji reactions, threads, and voice/video calls are all super nice to have.
I think my one major complaint with Element so far is the crypto(graphy) stuff. The Matrix protocol (and therefore Element, as a Matrix client) treats security incredibly seriously, and views end-to-end encryption as a must-have for any modern personal communications product. I appreciate this, and 100% agree! I just wish that it wasn't such a drag on the user experience.
Upon logging into Element for the first time, you're continuously prompted to do things like set up encryption key backups or set up cross-signing keys for verifying sessions across devices. A lot of the prompts are pretty vague and unhelpful, too:
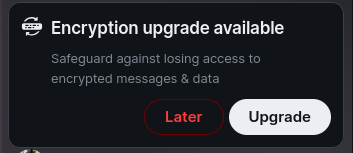
I can understand where the developers are coming from, to a degree. When you need end-users to do some chore like set up a password or backup or whatever, you want to prompt them in such a way that they think, "Ooo! A free upgrade! How deluxe, don't mind if I do!" rather than "Ugh, annoying popup, dismiss 👎". But when you click the popup to do whatever it wantsI'll break this specific prompt down, both for rubber-ducking and in case anyone else is curious/confused. Matrix encrypts all of your messages with an encryption key stored locally on your device. To make sure you don't lose the ability to decrypt your messages if you lose that device, you can backup your keys on the server. To avoid storing that encryption key in plaintext, the key itself is encrypted at rest on the server with a user-chosen passphrase and a long auto-generated recovery key. The app is basically prompting you to set up a passphrase and to write that recovery key down somewhere., the settings page isn't any more clear. The Security & Privacy settings page alone uses all of these technical terms for vaguely related things:
- Encryption keys
- E2E room keys
- Security Key
- Recovery key
- Recovery phrase
- Cross-signing keys
It doesn't help that a lot of their available documentation is outdated, and some of the above terms have been renamed to others, with different clients in different states of renaming. Part of me wants to go through client setup from scratch again just to fully understand all the different components at play, but most of the "Reset" options have pretty scary "You're gonna lose all your data!" dialogues.
I was about to write a long paragraph about how this might just be another
necessary evil of self-hosting software dealing with complicated
cryptographyAs the crypto(currency) people like to say - not your
keys, not your coins messages!, but that may not be the case!
At the time of writing, it was just announced that all of this is being
addressed in the 2.0
version of the Matrix
protocol. There's quite a bit of effort being put into Matrix Spec Proposals
(like RFCs, but for the Matrix protocol) around "Invisible Encryption"; a
variety of the proposed improvements should ideally make Matrix as user-friendly
as centralized alternatives like Signal or iMessage. Very exciting!
Anyway, that's enough rambling about Matrix. Back to the homelab!
Prometheus & Grafana
While Uptime Kuma is handy for alerting and basic healthchecks, I wanted a
"single pane of glass" to check all the usual metrics for machines in the
cluster: load average, network in/out, storage capacity, file I/O performance,
etc. Using Prometheus to collect the metrics and Grafana for displaying them in
nice dashboards is a classic combo, and it's dead
simple
to enable the node exporter in NixOS. I also installed
kube-state-metrics in
Kubernetes to get some Prometheus metrics for the state of various things in
Kubernetes.
I've admittedly been pretty lazy when it comes to Grafana. I've mostly just used
the open-source dashboards for things
like the node exporter metrics and kube-state-metrics, rather than creating my
own dashboards from scratch. Some of the stuff I've seen on
r/grafana is pretty impressive and makes me
jealous, but I'm a little too lazy to bother with learning the JSON/YAML DSL for
creating the dashboards.
These dashboards have definitely been nice to have, but I can't say that they
have helped me too much when dealing with outages. Whenever I get an Uptime Kuma
alert, I either already have a sense of what's wrong (it's always DNS!) or I
just check the logs for the service that's having trouble and it's immediately
obvious based on error messages. I'm kind of a noob when it comes to systems
performance stuff - I can just about grok every field in the output of the top
utility - so I usually use that stuff to confirm hypotheses when I feel like I
already have a decent idea of what's causing an outage, rather than constructing
a hypothesis from the bottom-up based on those lower-level metrics.
Reliability and Hardening
While adding all the new stuff was fun, it wasn't long until the Uptime Kuma notifications started to roll in to notify me of service outages. Many of them were cases of gun-pointed-at-foot syndrome specific to the configuration of the services themsevles, but a few of them were more pathological and rooted in the architecture of the homelab as a whole.
DNS
When I first set up Kubernetes, my DNS setup was dead simple. I had three nodes in the cluster:
heracles, the server nodeixion, an agent nodeathena, another agent node
heracles is the beefiest (although that's not saying much; it's a Pi 4 and the
others are Pi 3Bs), so I figured that I could treat it as the single point of
entry into the cluster. I added a DNS wildcard record for *.lab.janissary.xyz
to point to heracles, so any hostname not matching an existing one like
ixion.lab.janissary.xyz will get resolved to heracles' IP address. k3s runs
Traefik as a reverse proxy, and all
the services in the cluser have an IngressRoute that matches the Host header
of an HTTP/S request to the correct Service. The full lifecycle of an HTTPS
request to, say, prometheus.lab.janissary.xyz would be:
- Resolve
prometheus.lab.janissary.xyztoheracles' IP address, 1.2.3.4 - The HTTPS request goes to 1.2.3.4, where it hits port 443
- Traefik is exposed on port 443 via k3s' ServiceLB, and receives the request
- Traefik matches requests with a
Host: prometheus.lab.janissary.xyzheader to theIngressRoutefor Prometheus - The request is sent to the
Serviceand port specified by thatIngressRoute, and all the usual k8s networking goodness eventually gets it to the Prometheus container.
This worked well enough, and traffic got to where it needed to go.
The problem is that this leads to a single point of failure - if heracles goes
down for whatever reason, anything on the cluster becomes inaccessible (even if
the Pod in question is running on another node and is totally healthy). Making
all the cluster's incoming traffic go through a single node was not an
insignificant amount of load, either. heracles consistently had pretty high
load averages, even if the heavier containers like Jellyfin or qBittorrent were
scheduled onto other nodes.
I ended up solving this with some DNS load balancing. Instead of a single
*.lab.janissary.xyz record pointing to heracles, I had multiple
*.lab.janissary.xyz records pointing to each node in the k3s cluster. This
isn't perfect, since clients can still decide to cache a DNS record resolving to
a single unhealthy node and continue to send requests to it. It's better than
what was there previously though, since HTTP/S requests have a chance to go to
any node in the cluster rather than being guaranteed to go through heracles.
NFS & SQLite
A lot of containers need persistent storage for things like config files,
caching, databases, etc.. For most of these containers, I'd typically just make
an application-specific PersistentVolume on the NAS' NFS server, mount it, and
call it a day. This worked great for things that literally just need to store a
file or two, but I was getting terrible performance for things like Jellyfin
or the *arr suite that use an SQLite database and hammer it during periods of
high load.
As it turns out, NFS and SQLite do not play well together. My knowledge of filesystems is pretty limited, but from my research it seems to be related to a difference in file locking semantics between NFS and local filesystems, and SQlite's use of WAL (see "WAL does not work over a network filesystem"). This was not a fun rake to step on, considering the NFS server is kind of the only data storage that's available across the entire lab.
Fortunately for the *arr suite, there's a hidden setting to point the application to a PostgreSQL server instead of a local SQLite server. There's a tutorial on the Servarr wiki, but I still wish this stuff was exposed via environment variables or the Settings page of the applications' web UIs. I had to migrate all of my data from SQLite to PostgreSQL and that was a little bumpy, but it eventually worked after some manual dropping of tables and restarting.
Unfortunately for Jellyfin, it does not currently support using anything other than SQLite for the library database. This is a huge pain, since the library database gets absolutely thrashed when importing big TV shows or updating metadata in bulk. I ended up biting the bullet here and finally installing Longhorn to split the difference - I still get local storage that plays nicely with SQLite, but it replicates across all the nodes in the cluster so there's no real risk of data loss if one of the machines catches on fire. This is blessedly simple with k3s; there's a tutorial in the official docs, but I used Helm with a Helmfile to keep things reproducible.
Jellyfin now works like a charm for the most part, even when ingesting large seasons of shows or bulk-updating metadata for the entire media library. I feel a little nervous relying on Longhorn and its distributed systems black magic since I don't dream of understanding how it works under the hood, but I don't mind selling my soul to avoid some data loss.
Hardware
This is one issue that I feel pretty dumb for even running into. Every couple of
weeks, I would run into a weird error where any of the Pis could become totally
unresponsive for no apparent reason. I couldn't access any of the containers
scheduled onto the node, I couldn't SSH in, or even ping it - zilch. When I
would physically inspect the Pi sitting in the rack, it looked pretty much fine.
The power indicator light was solid, so it was definitely on. The Ethernet cable
would also always be firmly seated, so it wasn't a physical networking issue.
The only odd thing I could notice was that the data transmission LED would be
solid or dead, rather than blinking rapidly. The only thing that would fix it
would be unplugging and re-plugging the USB power cable into the Pi, after which
it would boot and behave normally.
I kept chalking this up to loose connectors or weird electrical gremlins or the
phase of the moon until I finally got sick of it and did some sleuthing. It
didn't take me too long in journalctl to find the cause of the issue - the Pis
were overheating! When I had installed the Pis onto the little plastic rack
thing I got on Amazon years ago, I had forgotten to put
on the heatsinks before I had screwed everything together. I told myself I
would install all the heatsinks later when I felt like unscrewing everything,
and I never got around to it. As expected, as soon as I took apart the rack and
installed the heatsinks, the issue disappeared and never came back.
I'm obviously disappointed in myself for my initial laziness, but also that I
hadn't just checked the logs after rebooting the first time. I didn't write down
in my notes what the exact log message was that let me know it was overheating,
but it was plain as day (basically along the lines of "Oct 09 08:46:08 ERROR ERROR IT'S HOT IN HERE"). I am curious, though, why the Pis stayed stuck in a
zombified state and didn't just shut down or reboot automatically. That probably
says more about my hardware knowledge than anything, though.
Conclusion
While the lab is still far from perfect, I'd say it's in a pretty good spot. Installing new services is pretty quick and easy, and having everything in a centralized, declarative format is even better than I expected it to be. The only glaring issue with it at the moment is capacity - a dinky little RasPis can only handle so much, especially when it comes to media streaming.
Fortunately, I have a pretty big addition to the lab to share - 1U big, to be exact! - but that'll have to wait until the next post.